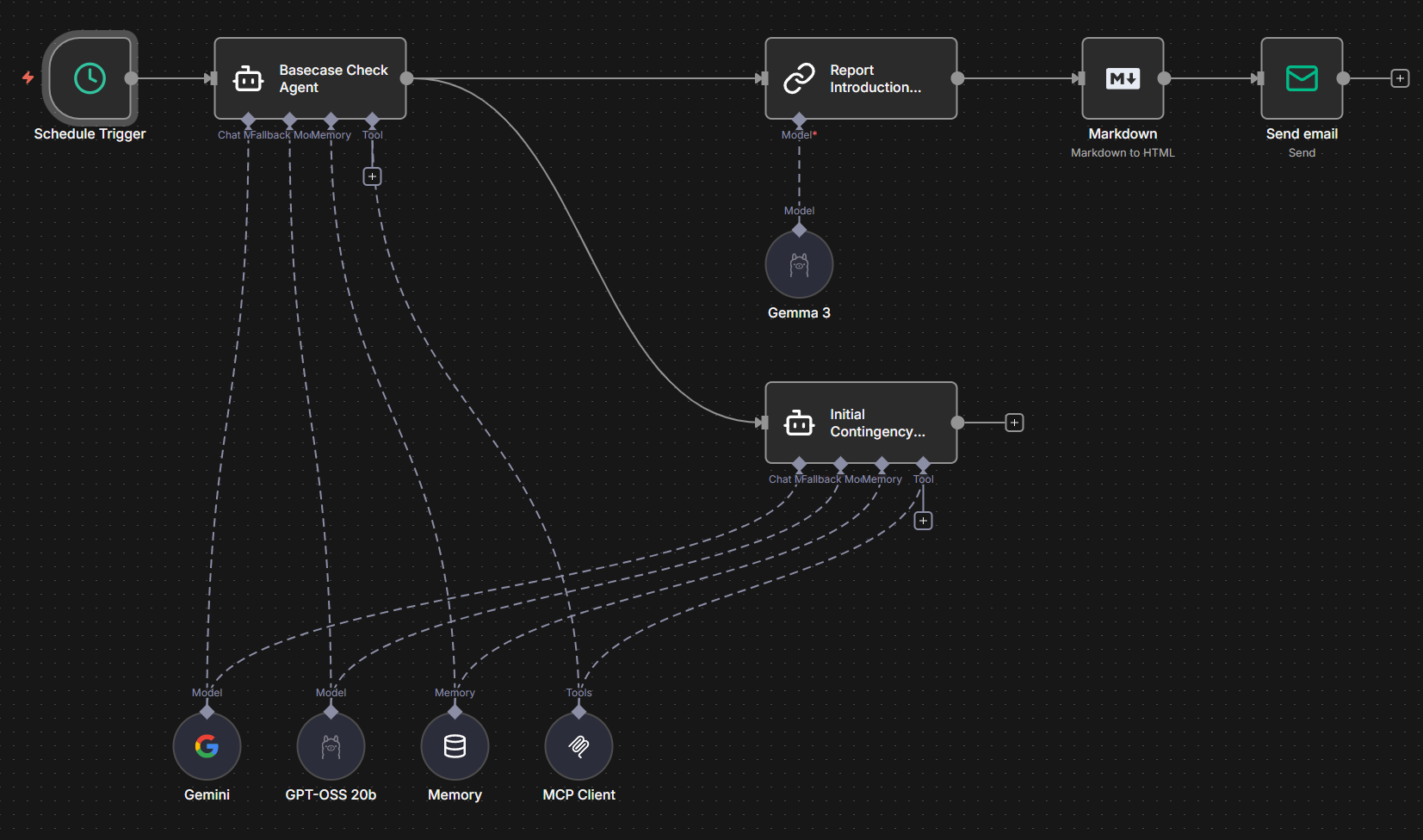
I’ve been contributing to Harvard’s PowerAgent project on Github (PowerAgent - Open-Source Agentic AI for Power Grids | Harvard SEAS) and have found it to be very fascinating to work with. The idea of PowerMCP is to translate JSON-formatted commands from any of a number of commercial or open-source Large Language Models (LLMs) into real actions in power flow software like PSS/E or PSLF. Then PowerWF uses N8N or LangGraph to setup automations - for example an automation that pulls a PSS/E format case from an FTP server, runs contingency analysis on the file, and provides a brief report back to the user on the system security. Basically a really easy way to setup real-time contingency analysis.
Recently I’ve been pretty swamped in the evenings and haven’t gotten to play with it very much, but I’m curious: what does everyone think about bringing in fine-tuned, local, offline AI models into power operations to help make faster, better informed real-time mitigation plans? Human operators can only test out so many ideas when under pressure, but a small army of AI models can check more mitigation ideas and maybe come to a more optimal solution that gets double checked by the engineer on staff?
This is a very interesting direction. I think the real opportunity is not necessarily LLMs operating power systems, but reducing the friction between human intent and deterministic analysis tools.
Using LLMs as an interface layer that translates structured instructions into workflows, orchestrates existing simulation engines, and generates summaries makes a lot of sense. Many power flow tools are powerful but still difficult to use without scripting expertise. Lowering that barrier could materially improve productivity and broaden access beyond core engineers.
I would be curious to learn more about the architectural safeguards:
Are LLM outputs constrained to validated templates or schemas when generating commands?
What deterministic validation exists between LLM output and execution in PSS/E or PSLF?
How do you ensure reproducibility and auditability of workflows, especially for operational or compliance-sensitive use cases?
The strongest near-term value seems to be in automation and workflow orchestration such as contingency studies, standardized reporting, and data ingestion pipelines, while keeping simulation engines as the authoritative decision layer.
If implemented carefully, this could meaningfully reduce cognitive and scripting overhead in planning and operations, which is where I see the biggest practical impact.
Would be interested to hear how you are thinking about guardrails and user trust as this evolves.
Are LLM outputs constrained to validated templates or schemas when generating commands?
The tool works by setting up JSON structured commands from the LLM. These are interpreted by a Model Context Protocol (MCP) server that listens for commands from the LLM and translates those requests into API queries from power flow programs like PSLF, PSS/E, TARA, or PowerWorld.
What deterministic validation exists between LLM output and execution in PSS/E or PSLF?
All simulation work is done deterministically by existing simulation software. Error messages are passed back to the LLM. You can also implement Human-in-the-loop in your workflow where results are passed to a human for review. This can be done by email, text message, Slack, whatever you want. The LLM basically asks for help or permission as requested in the workflow.
How do you ensure reproducibility and auditability of workflows, especially for operational or compliance-sensitive use cases?
All the output of the LLM including the thought process and problem solving are stored in the N8N workflow. Now it’s true, if you ask an LLM the same question over and over again it sometimes comes to different conclusions so I could see reproducibility being an issue. To be fair, this is a problem if you ask an engineer the same question in different contexts they can also be inconsistent. And engineers don’t do a great job writing down the entire chain-of-reasoning like an LLM can.